前言
在网页爬虫的时候往往我们需要破解验证码,这篇博文是为了论证如何依赖Python来识别验证码。
准备工作
首先我们需要安装PIL这个库。
Pillow相对于老版本的PIL好处已经在网上有很多,这里也不再介绍了。。。
提取图片文件
首先我们可以下载一个验证码包,你可以使用下面的命令下载:
这样就可以下载到验证码了。
比如这一张: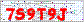
这样最后就能输出颜色的直方图:
颜色直方图的每一位数字都代表了在图片中含有对应位的颜色的像素的数量。
每个像素点可表现256种颜色,你会发现白点是最多(白色序号255的位置,也就是最后一位,可以看到,有625个白色像素)。红像素在序号200左右,我们可以通过排序,得到有用的颜色。
接下来,我们继续操作这个直方图:
这样就会按照顺序输出直方图中的原来值和对应的键值的序列了。
这样我们就得到了很多种颜色,而很明显的,在验证码里面我们只需要红色和灰色,其他的我们可以视为杂色排除。而通过这样我们就能过构造出一个灰色图出来。
这样我们就得到了只有红色和灰色的图像,这就比较容易辨识了。
提取单个字符
由于这种字符比较简单,我们就直接纵向切割,提取单个字符就可以了。
这样就输出:
这样就可以知道每个字符开始和结束的序列号。
对图像进行切割就可以得到字符了。
向量空间搜索
在这里我们使用向量空间搜索引擎来做字符识别,它具有很多优点:
- 不需要大量的训练迭代
- 不会训练过度
- 你可以随时加入/移除错误的数据查看效果
- 很容易理解和编写成代码
- 提供分级结果,你可以查看最接近的多个匹配
- 对于无法识别的东西只要加入到搜索引擎中,马上就能识别了。
当然它也有缺点,例如分类的速度比神经网络慢很多,它不能找到自己的方法解决问题等等。
举个例子,你有3篇文档,筛选出其中的单词作为特征,对应单词的数量作为特征的值。取n个单词就生成一个n维空间,而每一篇文档就是在这个空间中的矢量,我们只要计算矢量之间的角度就能得到文章的相似度了。
这样他就会计算两个Python的字典类型并且输出他们的相似度。
取大量验证码提取单个字符图片作为训练集合的工作,但只要是有好好读上文的同学就一定知道这些工作要怎么做,在这里就略去了。可以直接使用提供的训练集合来进行下面的操作。
iconset目录下放的是我们的训练集。
最后追加的内容:
下面就是全部代码了:
这样直接运行就可以得到我们的验证码信息了。
pytesser库
- pytesser依赖于PIL,因此需要先安装PIL模块,详见:http://wenyue.me/blog/278
- pytesser调用了tesseract,因此需要安装tesseract:
先用包管理器安装这几个库:1234sudo apt-get install libpng12-devsudo apt-get install libjpeg62-devsudo apt-get install libtiff4-devsudo apt-get install zlibg-dev
下载tesseract的源码包:http://tesseract-ocr.googlecode.com/files/tesseract-3.00.tar.gz
解压、cd到解压后目录下tesseract-3.00/
运行./configure -prefix=你想要安装到的路径,比如:
|
|
然后make & make install
将tesseract的运行脚本加到环境变量中,比如:
|
|
, 这个路径与刚才你configure的时候设置的路径有关
到http://code.google.com/p/tesseract-ocr/downloads/list页 面去下载最新的eng.traineddata.gz文件,解压后的eng.traineddata放到/home/pf-miles /installation/install/tesseract/share/tessdata目录下,注意,虽然tesseract的svn trunk里也有这个文件,但那个用不得,会报
|
|
错误,详见:http://www.uluga.ubuntuforums.org/showthread.php?p=10248384,所以一定要用http://code.google.com/p/tesseract-ocr/downloads/list这里下载的那一份
试一试:
|
|
OK,tesseract安装完毕
- 下载pytesser包:http://pytesser.googlecode.com/files/pytesser_v0.0.1.zip(目前是0.0.1版本), 解压…并cd到解压后的目录下
- 目录下有个“phototest.tif”图片文件作为测试用,直接在目录下写一个python脚本进行测试:
test.py:
from pytesser import * im = Image.open(‘phototest.tif’) text = image_to_string(im) print text
运行:
|
|
结果:
Thls IS a lot of 12 pornt text to test the
ocr code and see lf It works on all types
of frle format
lazy fox The qurck brown dog jumped
over the lazy fox The qulck brown dog
jumped over the lazy fox The QUICK
brown dog jumped over the lazy fox
The quick brown dog jumped over the
应该说准确率还令人满意吧
pytesser的验证码识别能力比较低,只能对规规矩矩不歪不斜数字和字母验证码进行识别,这里还是要介绍下它的用法。有关它的安装和python对应的模块可以参考http://wenyue.me/blog/tag/pytesser。
pytesser只能对tiff(tif)格式的图片文件进行识别,大部分网站的验证码图片不是tiff格式的,所以需要进行转换。可使用Image模块转化图片格式:
获取验证码的时候需要让对方服务器写如cookie,所以需要以下这段
然后再需要拿着这个opener去登录, 登录成功后的,再去请求其他需要登录的页面的时候也需要使用这个opener去urlopen